Finding correspondences between images is a fundamental problem in computer vision. In this paper, we show that correspondence emerges in image diffusion models without any explicit supervision. We propose a simple strategy to extract this implicit knowledge out of diffusion networks as image features, namely DIffusion FeaTures (DIFT), and use them to establish correspondences between real images. Without any additional fine-tuning or supervision on the task-specific data or annotations, DIFT is able to outperform both weakly-supervised methods and competitive off-the-shelf features in identifying semantic, geometric, and temporal correspondences. Particularly for semantic correspondence, DIFT from Stable Diffusion is able to outperform DINO and OpenCLIP by 19 and 14 accuracy points respectively on the challenging SPair-71k benchmark. It even outperforms the state-of-the-art supervised methods on 9 out of 18 categories while remaining on par for the overall performance.
Without any fine-tuning or correspondence supervision, DIFT is able to establish reasonable and accurate semantic correspondence, outperform previous weakly-supervised methods with a large margin, and even on par with the state-of-the-art supervised methods.
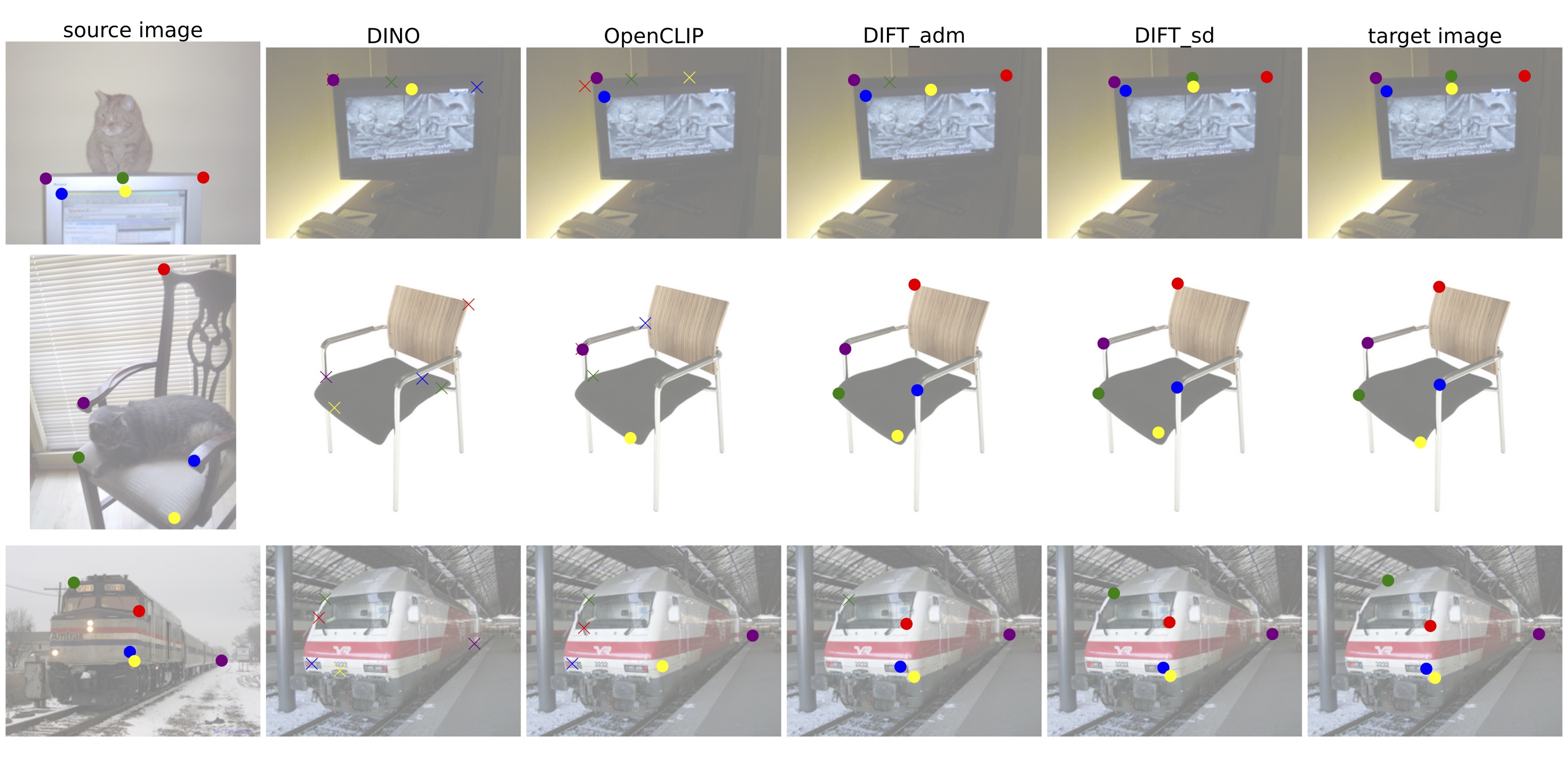
Compared to popular off-the-shelf features that (pre-)trained on similar data,
DIFT identifies better correspondences under occlusion, clustered scenes, viewpoint change, pose variants,
and instance-level appearance change,
outperforming its self-supervised learning counterpart feature (DIFT_sd vs. OpenCLIP; DIFT_adm vs. DINO) over 14 PCK points.
Below we visualize correspondence predictions using different features.
The leftmost image is the source image with a set of keypoints;
the rightmost image contains the ground truth correspondence for a target image
whereas any images in between contain keypoints found using feature matching
with various features. We use different colors to indicate different keypoints.
Circles indicate correctly-predicted keypoints and crosses for incorrect matches.




DIFT can easily propagate edits from one image to others across different instances, categories, and domains, without any correspondence supervision.
By using a small time step t, DIFT also shows competitive performance on geometric correspondence without any such supervision. Below we show the sparse matching results on HPatches using DIFT after removing outliers. We can see it works well under challenging viewpoint and illumination changes.



DIFT also demonstrates strong performance on temporal correspondence tasks, although never trained or fine-tuned on video data.
Here are the video segementation propagation results on DAVIS using DIFT.
Here are the human pose keypoints tracking results on JHMDB using DIFT.
This work was partially funded by NSF 2144117 and the DARPA Learning with Less Labels program (HR001118S0044). We would like to thank Zeya Peng for her help on the edit propagation section and the project page, thank Kamal Gupta for sharing the evaluation details in the ASIC paper, and thank Aaron Gokaslan, Utkarsh Mall, Jonathan Moon, Boyang Deng for valuable discussion and feedback.
@inproceedings{
tang2023emergent,
title={Emergent Correspondence from Image Diffusion},
author={Luming Tang and Menglin Jia and Qianqian Wang and Cheng Perng Phoo and Bharath Hariharan},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
url={https://openreview.net/forum?id=ypOiXjdfnU}
}